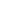技術干貨丨工業設備如何實現在線診斷?
什么是在線診斷?
ODS(Online Diagnosis Service)是MixIOT體系中的一個在線診斷服務組件。
“在線診斷”的定義比較復雜:
選擇一個長度合適的時間段,作為診斷的計算分析周期;
- 有明確的診斷對象;
- 有明確的、該對象需要診斷的“問題”;
- 有明確的、該對象所發生的一種或多種表象特征;
- 在計算分析周期內可以跟蹤記錄該對象的這些表象特征;
- 有預知的,或者可以預設的,一個或多個這些表象特征與問題之間概率關系;
- 有預知的,或者可以預設的,一個或多個表象特征之間的概率關系;
- 有預知的,或者可以預設的,一個或多個問題之間的概率關系;
以這些概率關系為條件,以計算周期內該對象的表象特征為依據,連續計算該對象會發生這些問題中的某一種(或某幾種)的概率。
這個定義實在是不太好懂,我們以人得病為例,逐個來解釋。
- 1. 要選擇一個合適的時間段作為計算周期。比如,是一天、一周,還是一個小時、一個月。假設我們選擇了一個月(30天),并不是說只從12月1日到12月31日,而是說,我們計算的數據是計算這個時候之前30天之內的數據,半年前的數據是不用的。一般來說,這個周期越長,診斷的可靠性就越高,但是,所需要消耗的算力也就越大,出結果就越久。具體要怎么選擇,還是需要根據實際情況。對那些時效性很強的問題,選擇太長時間周期的數據并沒有太大意義。但是如果周期選擇的太短, 很可能就診斷不出什么。
- 2. 要明確診斷的對象是誰,這個好理解。比如,一個人。
- 3. 我們需要有明確的可以診斷的“問題”,一個或者多個。這里說的問題,是一個人的病癥。這不是采集出來的,而是需要判斷出來的,比如“竇性心律不齊”,這就是一個問題。在ODS系統中,“問題”就是一個目錄。這個我們后面會講到。
- 4. 表象特征。這是我們能測量的,能采集的。比如體溫、血壓、血糖、膽固醇、心電圖、腦電波、X光片,或者咳嗽,吐血、便秘等,就像臨床癥狀。我們看到一個人的心電圖上波瀾起伏,這些都是客觀的表象特征,醫學上就叫臨床特征。而醫生根據這個心電圖和其他的體溫、血壓等,做出這個患者是“竇性心律不齊” 的判斷,這個是一個診斷結果。
- 5. 剛才說的這些表象特征,在計算周期之內我們是可以不斷采集到的,也是可以不斷統計計算出來的。
- 6. 預知的、預設的表象特征與問題之間的關系,就是臨床癥狀跟診斷結果之間的關系,比如,“血糖高” 是“竇性心律不齊” 這個病癥的概率是13%。這個是怎么來的,可能是之前的統計結果、研究結果,也可能是經驗。如果之前我們并沒有這個值,就可以設定一個值,未來等數據多了再去修改。
- 7. 表象之間的關系,這就像臨床癥狀之間的關系,比如血糖和血壓,血糖高同時血壓也高的概率是21%。
- 8. 問題之間的關系,比如竇性心律不齊(問題A)和冠心病(問題B)是兩個問題,有問題A的患者患問題B的概率是67%。
- 9. 最終的診斷結果就是基于這些表象特征數據(臨床癥狀)和相互關系而計算出來的。
我們在《工業互聯網核心引擎原理與實現》一書中,多次講過一個道理,工業設備(尤其是復雜的工業設備和裝置) 的機理是非常復雜的,我們看到的絕大多數故障的成因非常復雜,很難用簡單的因果關系來解釋。ODS實際上是提供了復雜的多元因素跟結果之間綜合關系的一個計算服務,理性科學地揭示多元因素對一個結果的共同作用的可能性,在沒有規律的地方發現規律。
表象特征和問題:
ODS 里面,表象特征和問題這兩個概念是比較難弄清楚的。
先說“問題” :“問題”就是我們已知的一些“疾病”的名稱,僅僅是名稱而已。要記住,這些名稱是醫學人士給的,不是“病癥”。這一點我們經常容易搞混。比如,小李今天請病假,你問他什么病,他可能會告訴你“發燒”。其實,發燒是可以用體溫計測量出來的,假設我們定義,體溫超過38攝氏度就是發燒,那么“發燒” 并不是“疾病”,而是“臨床癥狀”。小李去看醫生,醫生的診斷是“上呼吸道感染”,這才是“疾病”。如果小李去另一個醫院看病,另一個醫生可能診斷并不是 “上呼吸道感染”,而是“急性肺炎”,這也是“疾病”。
那么,會不會有某個醫生給小李的診斷結果是“旺火”這個疾病呢?不會!因為在醫生的字典里,并沒有“旺火”這個名字的疾病。小李是“上呼吸道感染”也好,“急性肺炎”也罷,不管是什么,診斷的結果都應該在醫生的疾病字典里面。換句話說,醫生是不會診斷出不在這個字典里面的疾病的。臨床癥狀與疾病的關系,可以用下圖來表示。

▲ 臨床癥狀X與已知疾病的概率關系
上圖的意思是,首先我們有一個“已知疾病”的字典,這就是我們的“ 問題表”;其次,我們還要有一個某個臨床癥狀與這些疾病之間概率關系的值。我們也可以倒過來說:疾病A、B、C會出現臨床癥狀 X 的概率分別是多少。
如果醫生只憑一個臨床癥狀就可以來診斷我們的病,那也未免太草率了。我們平時去醫院看病,都會抱怨醫生為什么要讓我們做這么多檢查,其實,這就是因為醫生希望得到多個表象特征。

▲ 臨床癥狀Y與已知疾病的概率關系
如圖臨床癥狀Y與已知疾病的概率關系。如果除了X,我們還能拿到另一個表象特征 Y,Y也與問題庫中的某些問題有對應的概率關系。見上圖。
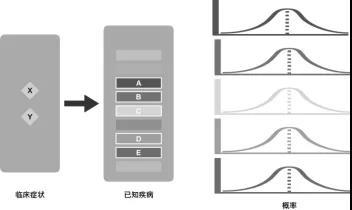
▲ 同時發生臨床癥狀X、Y與已知疾病的概率關系
那么,這個對象的兩個表象特征與問題表中問題項的概率關系,就變成了上圖這樣。我們就可以看到,有兩個表象特征的時候,對應問題B的概率就大了。
是不是表象特征越多,對定位問題就越準確呢?
表象特征和表象特征之間&問題和問題之間
上面我們說了,表象特征和問題之間的關系,感覺應該表象特征(臨床癥狀)信息越豐富、數據越多,問題(疾病)定位就應該越準確。這不能說是錯,但是并不準確。因為這種說法沒有考慮到兩個很重要的因素:一個是表象特征與表象特征之間的關系,一個是問題與問題之間的關系。
有時候,當一個表象特征(臨床癥狀)出現的時候,十有八九會伴隨著另一個表象特征的出現, 這個在醫學上叫“并發癥”;而有時候診斷出來一種疾病,很有可能還同時患有另一種疾病。
這就是所謂的表象之間、問題之間的關系。

▲ 表象之間的概率關系
這也是我們一個非常重要的計算依據。這些概率關系是需要預先設置的,見上圖。
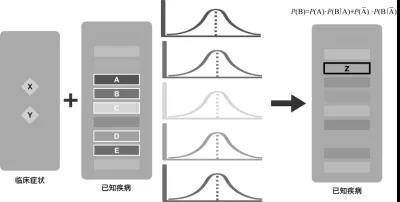
▲ 問題之間的概率關系
我們關注問題之間的關系,可以判斷是否還會有一種新的可能,這可以理解為隱藏更深的疾病,見上圖。
初級診斷和高級診斷
目前ODS還是個初級診斷模型,這是因為只用了一組診斷方法,即概率的方法,如下圖所示。從這個意義上講,現在的ODS只是一個連續計算復雜概率關系的計算器。
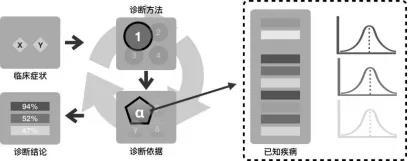
▲ 初級診斷示意圖
那么,高級診斷又是什么呢?那就是同時使用多組診斷方法,這樣就可以對診斷結果進行交叉驗證。
所謂診斷方法,就是診斷依據,概率的方法只是其中一種。當我們能引入第二種方法的時候,ODS就成為一個高級診斷,如下圖所示。

▲ 高級診斷示意圖
診斷報告
ODS是MixIOT體系中的一個服務組件,以項目形態來管理。首先需要創建ODS項目、設置項目屬性、寫腳本等,這個套路我們應該很熟悉了,就不花篇幅去說明了。具體怎么用還是需要去看ODS的使用指南,最重要的是掌握表象特征表達式的寫法,這個在使用指南里面有詳細的說明。
ODS的結果,是以診斷報告的形式輸出的。所謂診斷報告,其實也就是一個診斷結果的簡要文字描述。診斷報告生成的時間,是按診斷項目規定的診斷周期來確定的。
關于周期,這里有兩個概念,一個是診斷的時候用多久以來的數據,比如最近的一個月、一周還是多久;另一個就是診斷的間隔,多長時間去計算一次,一般來說可以一天一次,這樣,診斷報告就一天出一個。
▲ MixIOT系統中診斷報告界面
與其他的幾個服務組件不同的是,ODS需要做很多的基礎信息準備工作,這就是前面說的,表象特征與問題之間的概率關系,問題與問題之間的概率關系,表象與表象之間的概率關系。也就是所謂的“先驗概率表”,這是一個挺大的難題,是需要長期積累的,而我們之前未必已經有這方面的數據和信息,要想讓ODS發揮作用,還需要對這些基礎信息進行準備。
所以,ODS并不是一個立竿見影的東西,從我們啟用開始,到能真正產生作用, 還需要一些時間和積累。這就像我們要學完醫科畢業后,還要幾年實習,才能去開診所治病救人。
再論“問題”
ODS最核心的地方,就是“問題”。
盡管前面做了很詳細的介紹,但是要真正理解“問題”并不是一件容易的事情。所以,我們不得不回過頭來,再加以理論,因為這個概念稍有混淆,ODS就可能得出沒有意義的診斷結果。
首先要理解,“問題”就跟醫學上定義的“疾病”是一樣的,這只是一個主觀的定義,就是一個名稱,而不是一個現象。我們舉個例子,如果看到“美尼爾氏綜合癥”,你可能根本不知道這是什么,但是,這就是一個確定的疾病名稱。
一個患者被診斷為“美尼爾氏綜合癥”,是醫生根據患者的各種臨床癥狀“表象特征”給出的診斷結果,表象特征是客觀的,診斷卻是基于客觀依據的主觀行為。換句話說,“美尼爾氏綜合癥”是一個客觀存在的名稱,臨床特征也是客觀存在的事實,診斷是醫生把這些客觀存在的“臨床特征”與“美尼爾氏綜合癥”這個客觀存在的疾病名稱關聯起來的一個主觀行為。所以,另一個醫生有可能把相同的“臨床特征”與“地中海貧血”關聯起來也不一定。
這可能是ODS在實際使用中存在的最大問題,很多人嘗試用ODS去診斷故障的發生,這是沒問題的。但是如果這個故障我們本身就能采集到,是無須去診斷的。我們要診斷的是問題,這個問題可能是故障,也可能是故障背后的原因。

▲ 設備表象與診斷問題
ODS與線索構造
在MixIOT體系中,我們討論過“線索構造方法”,并介紹了把線索構造方法用于判斷 Aprus適配器問題的應用(Aplec)。你現在一定在想,線索構造也是用來發現問題的,ODS也是診斷問題,它們不是一個東西嗎?它們的區別又是什么?在實際項目中,我們是用線索構造方法好呢,還是用ODS診斷好呢?
“線索構造方法”跟ODS其實是兩回事,“線索構造方法”是去構造“與某個概率事件有一定關系”的“線索”集合的方法。我們上面的例子,只是用線索構造方法來判斷適配器是不是有問題而已。
在ODS里面,我們需要有一個先驗概率表,就是我們需要已經掌握很多“某個特征表象跟某個問題之間概率關系”的信息,這有點像“老師傅的經驗”,如果我們之前完全沒有這方面積累,那這個ODS我們也沒法用得很好。
“線索構造”不是“經驗”,而是“推理”。比如,如果平臺收到一個適配器的N報文,我們就可以肯定,這個適配器在收到這個報文的前4個小時肯定是在工作的;如果我們把該適配器最近4個小時的全部報文拿出來看看,沒有發現其中有I報文,那我們還可以肯定,這個適配器在前面4個小時里面肯定沒有重啟過;如果最近4個小時的報文里面,R報文超過480個,也就是平均每30秒有一個,那我們至少可以認定之前的4個小時里面的工作是“基本正常”的;如果最近4個小時報文中,我們還能看到一個D報文,而且這個報文中診斷是正常的,那么我們就可以根據剛才說的幾條線索:
● 有一個N報文;
● 沒有I報文;
● R報文有480個;
● D報文自診斷沒問題。
來斷定這個適配器是OK的。
說到這里我們順便說一下另一個話題。本文介紹的ODS也好,之前介紹過的“線索構造”也好,它們的目的都是為了去“判斷”或者“識別”,如果我們往大里說,這就有點“人工智能”的味道。實際上,“人工智能”有三個分支:以推理為主的、以知識和經驗為主的和以學習為主的。以學習為主的這個分支,就是所謂的“機器學習”分支。我們都知道,機器學習需要大量的“學習資料”,如果沒有這些學習資料,那機器學習也就只能是無米之炊。
雖說工業物聯網是當下熱點,但畢竟也還處于起步階段,工業企業在“學習資料”方面的積累基本為零。所以,我們事實上并沒有辦法一步到位,只能老老實實從“推理”開始,逐步積累“知識和經驗”,把這些“推理”的結果、“知識和經驗” 形成“學習資料”,才可能最終進化到真正的“機器學習+人工智能”。




如有疑問或想了解更多,請咨詢:0755-23740592