技術干貨丨靈活使用MixIOT解決各種問題
MixIOT里面能提供的東西是確定的,比如統計計算,是命題式的周期統計計算,而且它能支持的計算方法也是確定的。但是,現實中的需求卻是不確定的,在遇到現有的服務組件不能滿足,或者不能完全滿足實際需求的時候,我們該怎么做呢?下面通過兩個例子,來對這個問題做個解釋。
實例一:
假設,我們通過映射表,形成了一個對象,該對象里面有99個FV,S001~S099。該對象的數據,是以數據拼圖(馬賽克)方式保存在時序數據庫里面。
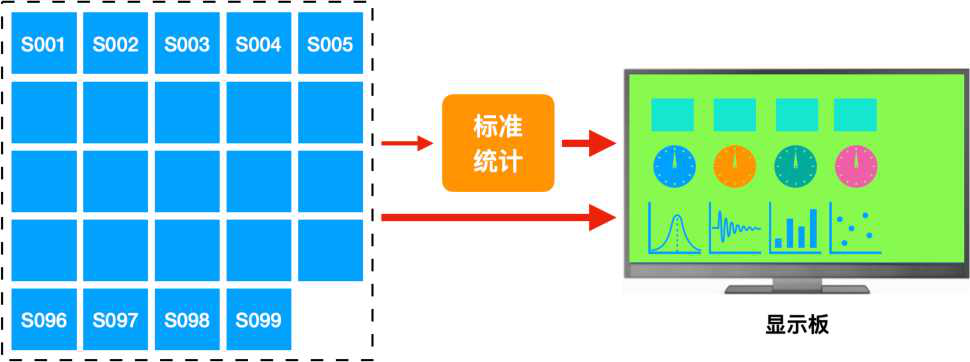
我們可以用Dashboard(顯示板)把這些時序數據實時顯示出來,還可以做各種統計計算,這些都是很熟悉流程。
如果有這么一個需求,需要實時做這樣一個計算:

這是一個FV的計算,但是,涉及到的數據,并不是當前FV的值,而是過往FV的值,而且公式里面很多東西可能會變,比如,FV會變,“最近多少個”也會變。
很顯然,在MixIOT里面找不到能夠做這個計算的應用,也就是說,無論如何,都要做一個新的應用,這個應用的每個項目,就是確定這些FV和“最近多少個”。

我們把公式里面可變的東西提煉出來,變成9個參數。這個應用就用PHP或別的工具來開發,利用API-X 等獲取需要的數據,然后每5秒鐘計算—次。應用開發好了,創建第一個項目,每30秒鐘計算一次:
參數1=30,參數2=“S031”,參數3=45,參數4=“S038”,參數5=60,參數6=“S064”,參數7=“S071”,參數8=120,參數9=“S062”
這一類公式的計算,我們隨便取個名字叫“杰克遜估計值”,然后,可以在離線數據里面,創建一個標識,比如JacksonEV。應用把這個值算出來后,就通過API-Q插入到離線數據表(Collectos)。這樣的話,以離線數據JacksonEV為標識的數據,每30秒就有一個。
接下來,就是要解決這個計算出來的“杰克遜估計值”的顯示的問題了。把原來這個對象的映射表稍微修改一下,增加一個FV,比如,S100:
[“S100”, “JacksonEV”, “杰克遜估計值”,…,&Collectos("JacksonEV”), ...]
那么,該對象就多了一個FV。
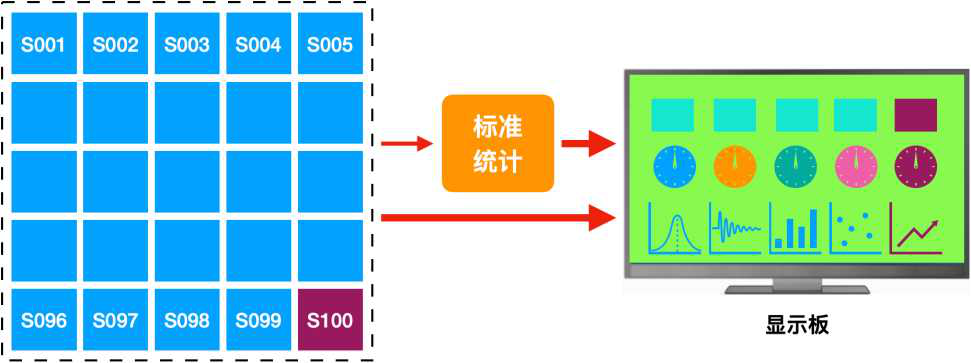
既然這個計算值X已經變成了這個對象FV的一員了,就享有跟別的FV一樣的待遇,可以在顯示板上顯示(卡片,儀表,曲線等等),參與統計計算,參與數據分析。
除了這個“杰克遜估計值”,還會經常計算另一個值,我們姑且稱之為“瓦西姆估計值”,計算公式是這樣的: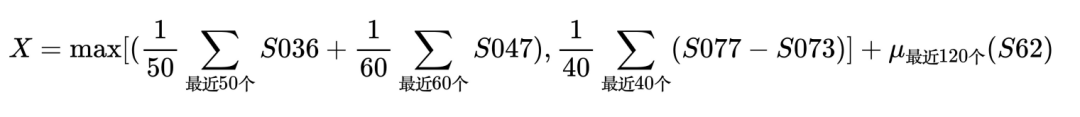
一樣的,把這個計算也納入應用,把計算結果以“WaximaEV”作為標識。創建項目的時候,可以選擇是要計算杰克遜還是瓦西姆,如果是杰克遜,就用JacksonEV為離線標識寫到Collectos,如果是瓦西姆,就用Waxima為離線標識寫到Collectos。
總結一下,這其實就是離線數據的用法了,離線數據在MixIOT中是一個機制,應該學會靈活運用,舉一反三,活學活用。
實例二:
某企業有4臺設備夜以繼日生產產品,該企業要對12個工人進行績效管理,以績效決定工資。績效工資的計算不僅與產品的產量和良品率有關,還與設備的故障率、開機率、設備能耗有關。假設通過MixIOT標準的統計和計算能夠計算出每個小時里的這些值。
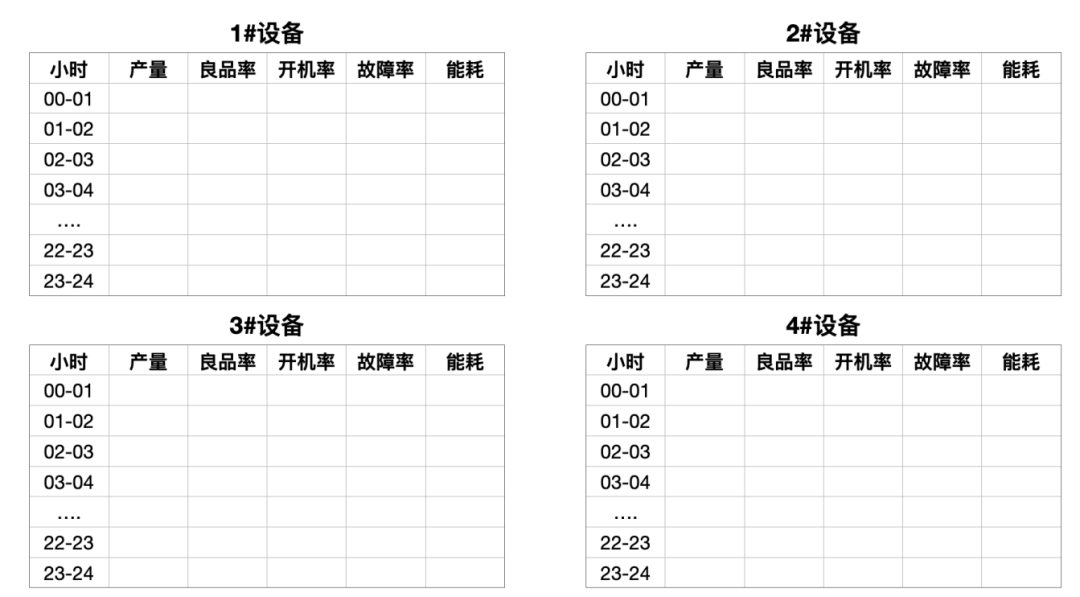
每小時的績效考核工資計算的公式是這樣的:

從這個公式可以看出,每小時的績效工資,是每小時的基本工資48.5元加上產量績效,減去不良品率績效,加上開機率績效,減去故障率績效,再加上節能績效。
在MixIOT中,不管是馬賽克時序數據,統計數據還是離線數據,其實都有兩個屬性,一個是標識,一個是時間。MixIOT的機制是不允許修改的,MixIOT的統計計算是標準的,不允許對數據增加別的屬性,也增加不了。
那么問題來了,數據并沒有工人的屬性,該怎么去計算工人的績效工資呢?
在MixIOT中,可以用一個標準的方式來解決這類的問題。分兩步走:
第一步,創建工人與這些數據屬性的“關聯關系索引”;
第二步,做一個應用,以這個“關聯關系索引”去組織需要的數據,進行計算,并保存計算結果。
所謂創建工人跟這些數據屬性的關聯關系,一個是時間,一個是標識,說白了,就是建立一個表:
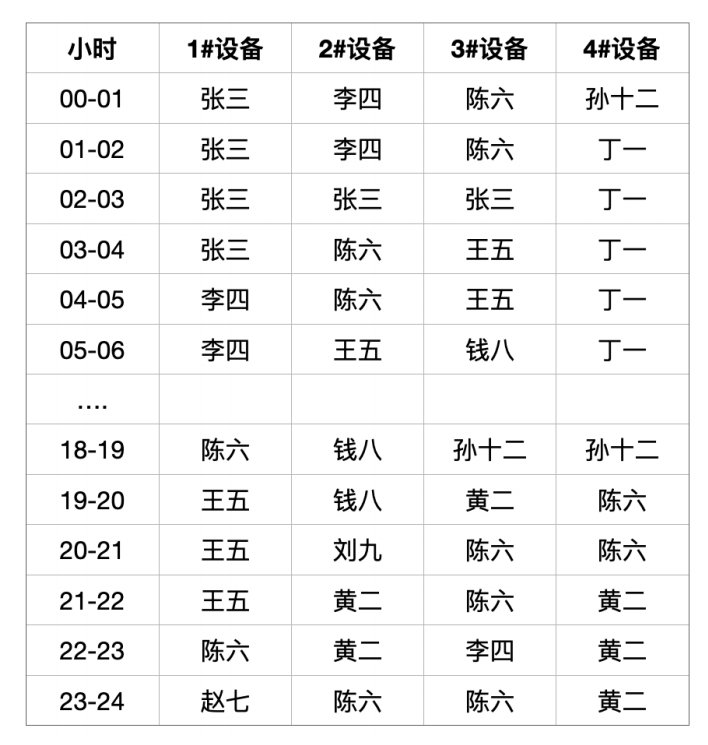
這其實就是一個排班表了,這個排班表,隨時可以變。計算績效工資,每小時計算一次,并把記錄保存起來。這樣,一個月,我們就把這些計算結果都加起來,就是工人這一個月的績效工資。
MixIOT中,需要有這么一個排班表,通常這樣的表都是在客戶的諸如ERP系統、CRM系統或者是員工管理系統里面。假設,是來自工廠的工人排班管理系統,應用通過一個接口,每小時去更新一次。
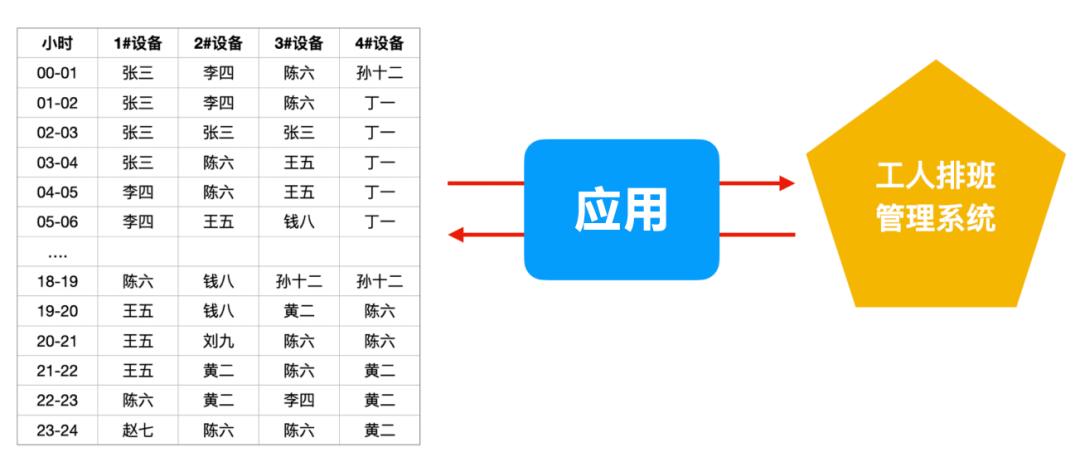
我們在這個應用里面,維持了一個“關聯關系索引”表。而且,這個表是與工廠的工人排班管理系統同步的,至于這個排班管理系統的數據是怎么來的,也許是工人上班打卡,也許是別的什么方式,我們不用去管。

有了這個表,下面的事情就很顯然了。這是第一步。
第二步,我們讓這個應用,打開另外一個表,記錄計算結果:
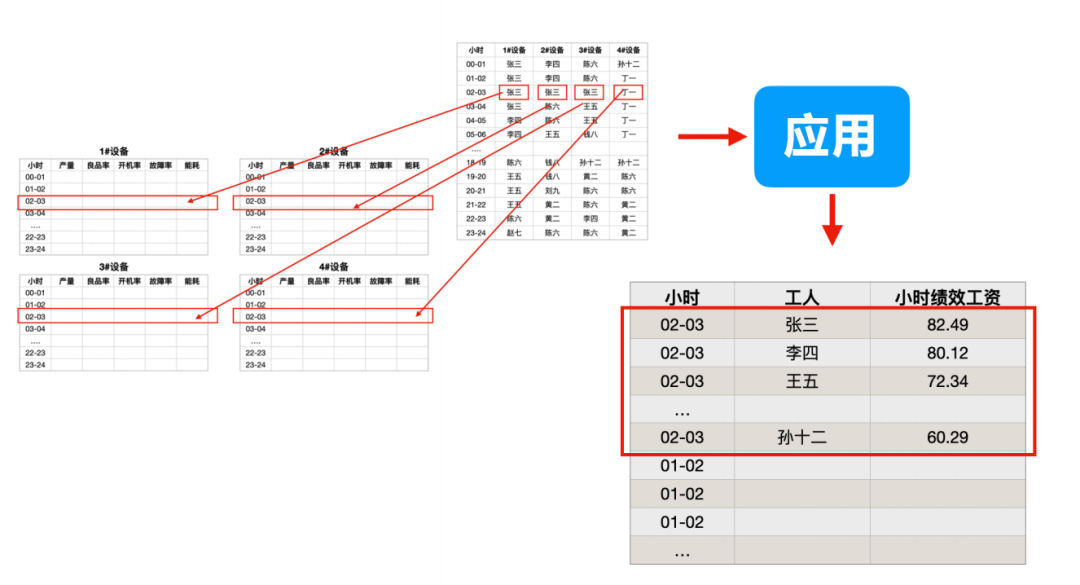
后面怎么去加加減減的,算出工人每個月的績效工資,就不在這里細說了。
下面說一個另外的一種情況。假如,排班的情況不是實現計劃好的,而是根據工人實際打卡的情況而來,也就是說,某臺設備從張三換到李四,并不是在整點發生,可能張三在1#機臺的實際時間,是09:22-15:42。李四的站臺時間是15:42-22:34,那又該如何呢?
其實,做法是一樣的,只是稍微復雜一些:
1、這個“關聯關系索引”方式的表述有所不同;
2、需要對“統計結果數據”進行“分割”。
先來解釋上面第二點。
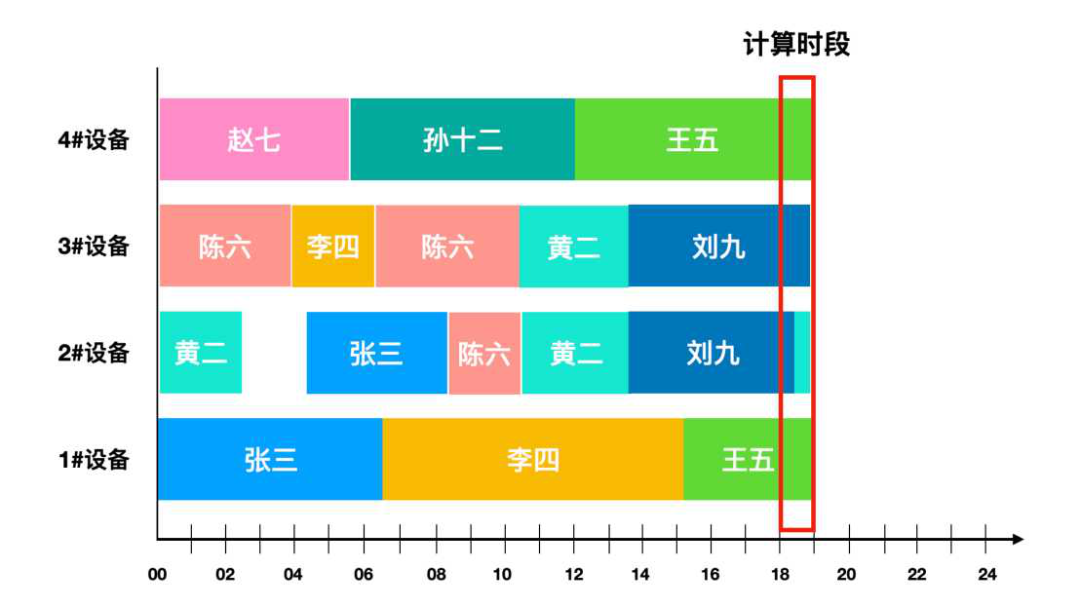
MixIOT的統計,是標準的,周期的。比如,計算15-16這個統計時段,在MixIOT中是無法改變的。假設1#機臺算出來,在15-16這個時段的績效工資是82.36元。但是,這一個小時,張三和李四是分別站臺的:
張三,15:00-15:42;李四,15:42-16:00
MixIOT統計計算的時候,不會理會這個小時是誰在站臺。那么,1#機臺的業績,是張三和李四共同的貢獻,這沒辦法再精細了,只能平均分配或者根據站臺時長按比例分配吧。
再解釋第一點。
前面說的“排班表”,是一種靜態的“關聯關系索引”,盡管這個排班表隨時可以更新,但畢竟是預先準備的,所以,我們把這組索引歸置為靜態索引。
除了靜態索引,還有一種“動態索引”。
我們通過一個規則,在計算時段準備計算的時候,去獲取該計算區間到底誰在站臺。
那么,上面這張圖是怎么被記錄下來的呢?這里就需要引入一個概念,叫“Check-In”和“Check-Out”,就像住酒店的時候,辦理入住就叫Check-In,走人的時候退房,就叫“Check-Out”。
這個Check-In和Check-Out的方式可能是打卡、App、按指紋、掃碼、人臉識別等等。
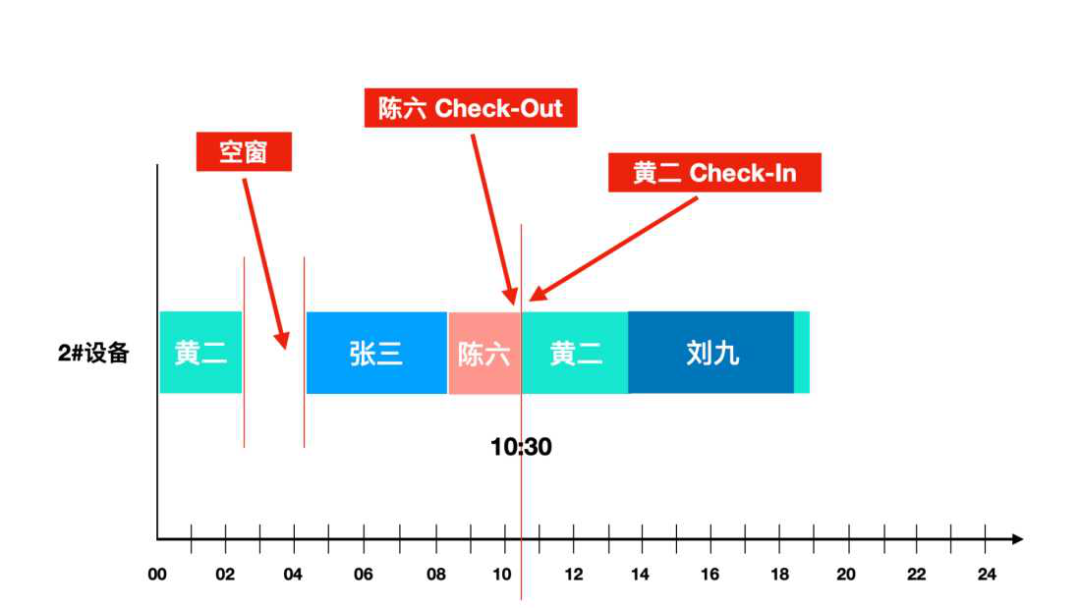
Check-In和Check-Out,上面的圖已經說得很清楚了,只需要掌握兩個原則:
第一,如果一個設備機臺只能有一個位置Check-In,那么,只要有Check-In,前面的一個就被自動Check-Out。無論前一個人是走了,還是沒走,什么時候走的,走的時候有沒有打卡。即便Check-Out過一段再打卡,也不做記錄;
第二,某個設備機臺,在Check-Out之前,如果沒有Check-In發生,就視為前一個Check-In—直有效。Check-Out后,到下一個Check-In之前,這個叫空窗。如上圖,如果黃二走了,張三沒來,中間有一段時間是空窗。空窗期怎么處理,那就看需求按什么規則了,這里不再細說。




如有疑問或想了解更多,請咨詢:0755-23740592